
[ad_1]
Novo Nordisk is a number one international pharmaceutical firm, liable for producing life-saving medicines that attain greater than 34 million sufferers every day. They do that following their triple backside line—that they need to attempt to be environmentally sustainable, socially sustainable, and financially sustainable. The mix of utilizing AWS and knowledge helps all these targets.
Information is pervasive all through the whole worth chain of Novo Nordisk. From foundational analysis, manufacturing traces, gross sales and advertising and marketing, medical trials, pharmacovigilance, by patient-facing data-driven purposes. Subsequently, getting the muse round how knowledge is saved, safeguarded, and utilized in a approach that gives essentially the most worth is likely one of the central drivers of improved enterprise outcomes.
Along with AWS Professional Services, we’re constructing an information and analytics answer utilizing a contemporary knowledge structure. The collaboration between Novo Nordisk and AWS Skilled Providers is a strategic and long-term shut engagement, the place builders from each organizations have labored collectively carefully for years. The info and analytics environments are constructed round of the core tenets of the information mesh—decentralized area possession of knowledge, knowledge as a product, self-service knowledge infrastructure, and federated computational governance. This permits the customers of the setting to work with knowledge in the best way that drives one of the best enterprise outcomes. We’ve mixed this with components from evolutionary architectures that can permit us to adapt completely different functionalities as AWS repeatedly develops new companies and capabilities.
On this sequence of posts, you’ll find out how Novo Nordisk and AWS Skilled Providers constructed an information and analytics ecosystem to hurry up innovation at petabyte scale:
- On this first publish, you’ll find out how the general design has enabled the person parts to return collectively in a modular approach. We dive deep into how we constructed an information administration answer primarily based on the information mesh structure.
- The second publish discusses how we constructed a belief community between the programs that comprise the whole answer. We present how we use event-driven architectures, coupled with using attribute-based entry controls, to make sure permission boundaries are revered at scale.
- Within the third publish, we present how end-users can devour knowledge from their software of alternative, with out compromising knowledge governance. This contains find out how to configure Okta, AWS Lake Formation, and Microsoft Energy BI to allow SAML-based federated use of Amazon Athena for an enterprise enterprise intelligence (BI) exercise.
Pharma-compliant setting
As a pharmaceutical trade, GxP compliance is a mandate for Novo Nordisk. GxP is a basic abbreviation for the “Good x Observe” high quality pointers and laws outlined by regulators comparable to European Medicines Company, U.S. Meals and Drug Administration, and others. These pointers are designed to make sure that medicinal merchandise are protected and efficient for his or her meant use. Within the context of an information setting, GxP compliance includes implementing integrity controls for knowledge used to in resolution making and processes and is used to information how change administration processes are applied to repeatedly guarantee compliance over time.
As a result of this knowledge setting helps groups throughout the entire group, every particular person knowledge proprietor should retain accountability on their knowledge. Options had been designed to supply knowledge homeowners autonomy and transparency when managing their knowledge, enabling them to take this accountability. This contains the aptitude to deal with personally identifiable data (PII) knowledge and different delicate workloads. To offer traceability on the setting, audit capabilities had been added, which we describe extra on this publish.
Answer overview
The complete answer is a sprawling panorama of unbiased companies that work collectively to allow knowledge and analytics with a decentralized knowledge governance mannequin at petabyte scale. Schematically, it may be represented as within the following determine.
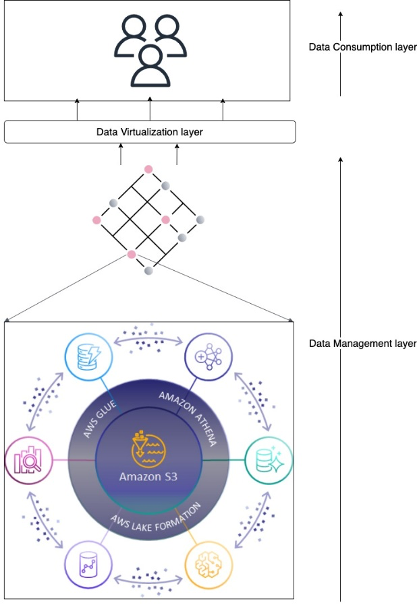
The structure is cut up into three unbiased layers: knowledge administration, virtualization, and consumption. The tip-user sits within the consumption layer and works with their software of alternative. It’s meant to summary as a lot of the AWS-native assets to software primitives. The consumption layer is built-in into the virtualization layer, which abstracts the entry to knowledge. The aim of the virtualization layer is to translate between knowledge consumption and knowledge administration options. The entry to knowledge is managed by what we check with as knowledge administration options. We focus on one in every of our versatile knowledge administration options later on this publish. Every layer on this structure is unbiased of one another and as a substitute solely depends on well-defined interfaces.
Central to this structure is that entry is encapsulated in an AWS Identity and Access Management (IAM) function session. The info administration layer focuses on offering the IAM function with the appropriate permissions and governance, the virtualization layer supplies entry to the function, and the consumption layer abstracts using the roles within the instruments of alternative.
Technical structure
Every of the three layers within the total structure has a definite accountability, however no singular implementation. Consider them as summary lessons. They are often applied in concrete lessons, and in our case they depend on foundational AWS companies and capabilities. Let’s undergo every of the three layers.
Information administration layer
The info administration layer is liable for offering entry to and governance of knowledge. As illustrated within the following diagram, a minimal assemble within the knowledge administration layer is the mix of an Amazon Simple Storage Service (Amazon S3) bucket and an IAM function that offers entry to the S3 bucket. This assemble could be expanded to incorporate granular permission with Lake Formation, auditing with AWS CloudTrail, and safety response capabilities from AWS Security Hub. The next diagram additionally exhibits {that a} single knowledge administration answer has no singular span. It may well cross many AWS accounts and be comprised of any variety of IAM function combos.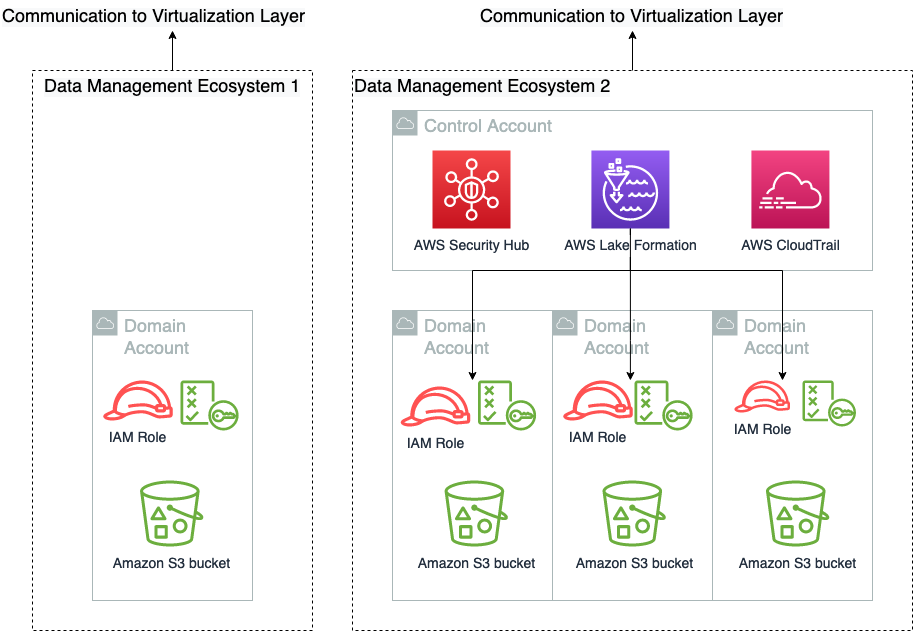
We’ve purposely not illustrated the belief coverage of those roles on this determine, as a result of these are a collaborative accountability between the virtualization layer and the information administration layer. We go into element of how that works within the subsequent publish on this sequence. Information engineering professionals typically interface straight with the information administration layer, the place they curate and put together knowledge for consumption.
Virtualization layer
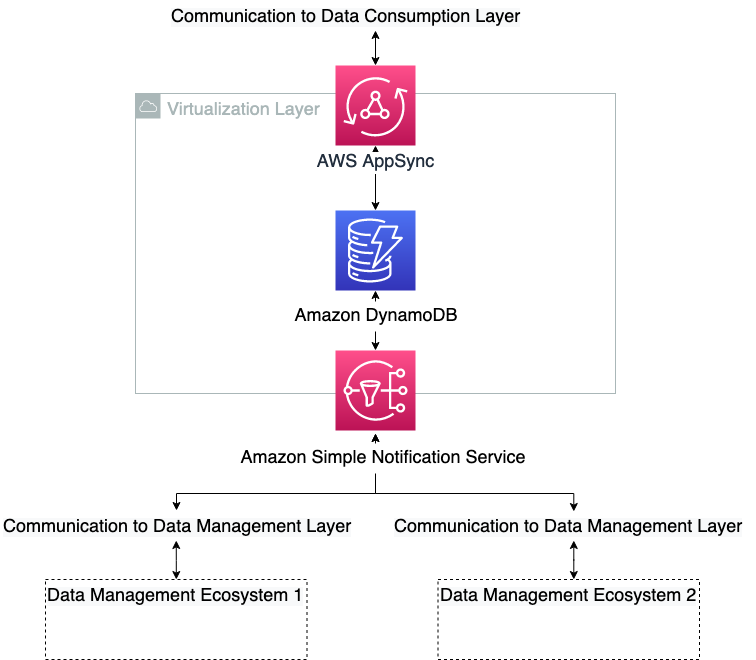
The aim of the virtualization layer is to maintain observe of who can do what. It doesn’t have any capabilities in itself, however interprets the necessities from the information administration ecosystems to the consumption layers and vice versa. It permits end-users on the consumption layer to entry and manipulate knowledge on a number of knowledge administration ecosystems, in line with their permissions. This layer abstracts from end-users the technical particulars on knowledge entry, comparable to permission mannequin, function assumptions, and storage location. It owns the interfaces to the opposite layers and enforces the logic of the abstraction. Within the context of hexagonal architectures (see Developing evolutionary architecture with AWS Lambda), the interface layer performs the function of the area logic, ports, and adapters. The opposite two layers are actors. The info administration layer communicates the state of the layer to the virtualization layer and conversely receives details about the service panorama to belief. The virtualization layer structure is proven within the following diagram.
Consumption layer
The consumption layer is the place the end-users of the information merchandise are sitting. This may be knowledge scientists, enterprise intelligence analysts, or any third get together that generates worth from consuming the information. It’s essential for this sort of structure that the consumption layer has a hook-based sign-in stream, the place the authorization into the applying could be modified at sign-in time. That is to translate the AWS-specific requirement into the goal purposes. After the session within the client-side software has efficiently been began, it’s as much as the applying itself to instrument for knowledge layer abstraction, as a result of this will likely be software particular. And that is an extra essential decoupling, the place some accountability is pushed to the decentralized items. Many trendy software program as a service (SaaS) purposes assist these built-in mechanisms, comparable to Databricks or Domino Data Lab, whereas extra conventional client-side purposes like RStudio Server have extra restricted native assist for this. Within the case the place native assist is lacking, a translation right down to the OS person session could be performed to allow the abstraction. The consumption layer is proven schematically within the following diagram.
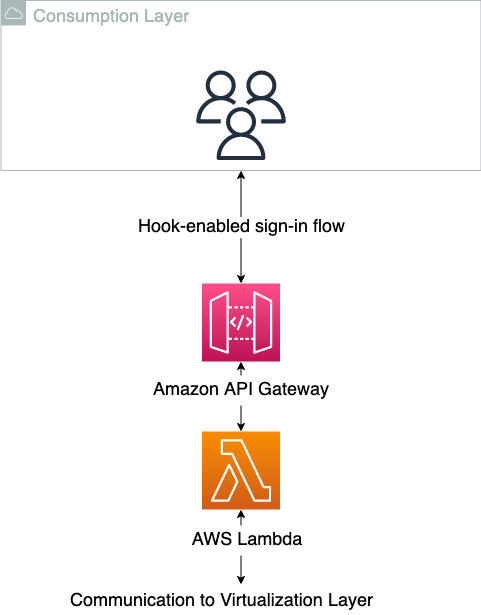
When utilizing the consumption layer as meant, the customers don’t know that the virtualization layer exists. The next diagram illustrates the information entry patterns.
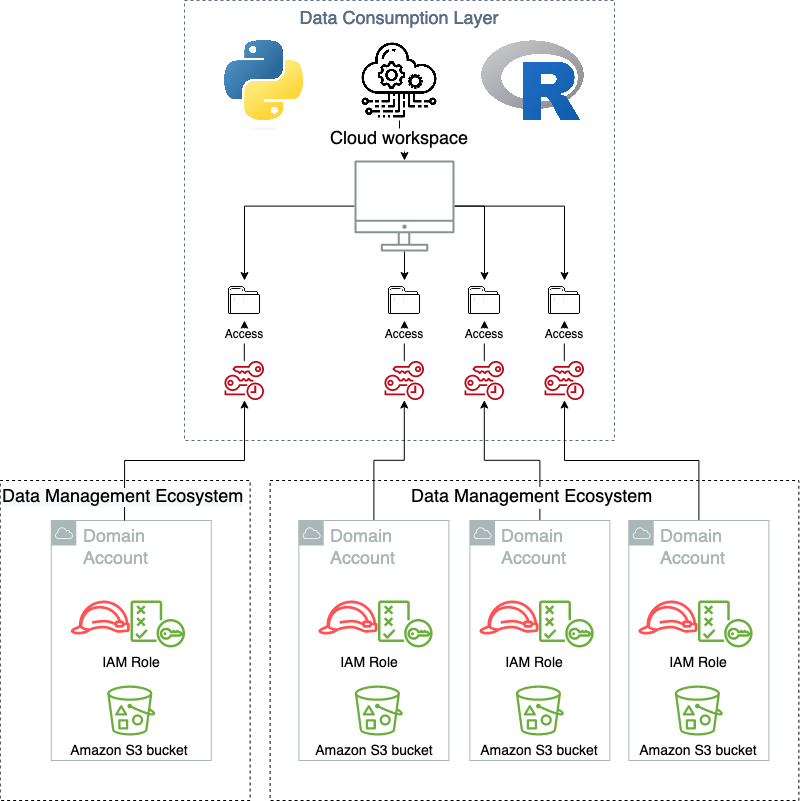
Modularity
One of many major benefits of adopting the hexagonal structure sample, and delegating each the consuming layer and the information administration layer to major and secondary actors, signifies that they are often modified or changed as new functionalities are launched that require new options. This offers a hub-and-spoke kind sample, the place many various kinds of producer/client kind programs could be linked and work concurrently in union. An instance of that is that the present answer working in Novo Nordisk helps a number of, simultaneous knowledge administration options and are uncovered in a homogenous approach within the consuming layer. This contains each an information lake, the information mesh answer introduced on this publish, and several other unbiased knowledge administration options. And these are uncovered to a number of varieties of consuming purposes, from customized managed, self-hosted purposes, to SaaS choices.
Information administration ecosystem
To scale the utilization of the information and improve the liberty, Novo Nordisk, collectively with AWS Skilled Providers, constructed an information administration and governance setting, named Novo Nordisk Enterprise DataHub (NNEDH). NNEDH implements a decentralized distributed knowledge structure, and knowledge administration capabilities comparable to an enterprise enterprise knowledge catalog and knowledge sharing workflow. NNEDH is an instance of an information administration ecosystem within the conceptual framework launched earlier.
Decentralized structure: From a centralized knowledge lake to a distributed structure
Novo Nordisk’s centralized knowledge lake consists of two.3 PB of knowledge from greater than 30 enterprise knowledge domains worldwide serving over 2000+ inside customers all through the worth chain. It has been working efficiently for a number of years. It is likely one of the knowledge administration ecosystems at the moment supported.
Throughout the centralized knowledge structure, knowledge from every knowledge area is copied, saved, and processed in a single central location: a central knowledge lake hosted in a single knowledge storage. This sample has challenges at scale as a result of it retains the information possession with the central group. At scale, this mannequin slows down the journey towards a data-driven group, as a result of possession of the information isn’t sufficiently anchored with the professionals closest to the area.
The monolithic knowledge lake structure is proven within the following diagram.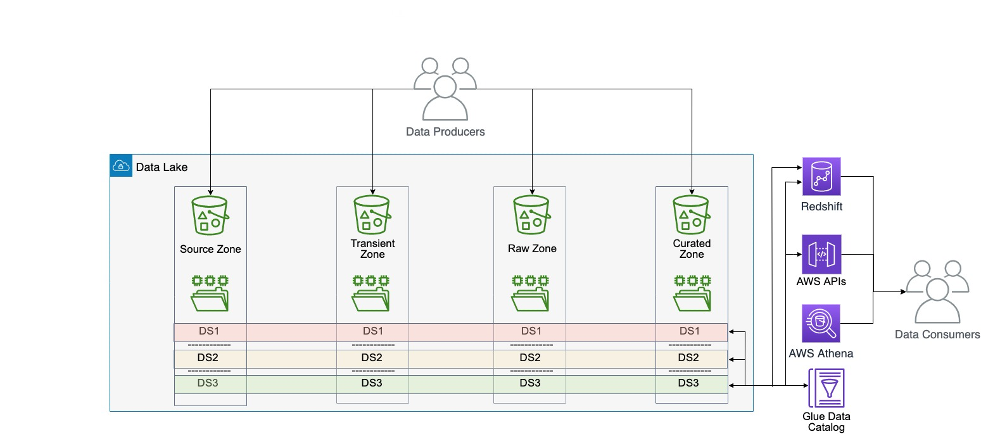
Throughout the decentralized distributed knowledge structure, the information from every area is stored inside the area by itself knowledge storage and compute account. On this case, the information is stored near area consultants, as a result of they’re those who know their very own knowledge finest and are finally the proprietor of any knowledge merchandise constructed round their knowledge. They typically work carefully with enterprise analysts to construct the information product and subsequently know what good knowledge means to shoppers of their knowledge merchandise. On this case, the information accountability can also be decentralized, the place every area has its personal knowledge proprietor, placing the accountability onto the true homeowners of the information. Nonetheless, this mannequin won’t work at small scale, for instance a corporation with just one enterprise unit and tens of customers, as a result of it will introduce extra overhead on the IT group to handle the group knowledge. It higher fits giant organizations, or small and medium ones that wish to develop and scale.
The Novo Nordisk knowledge mesh structure is proven within the following diagram.
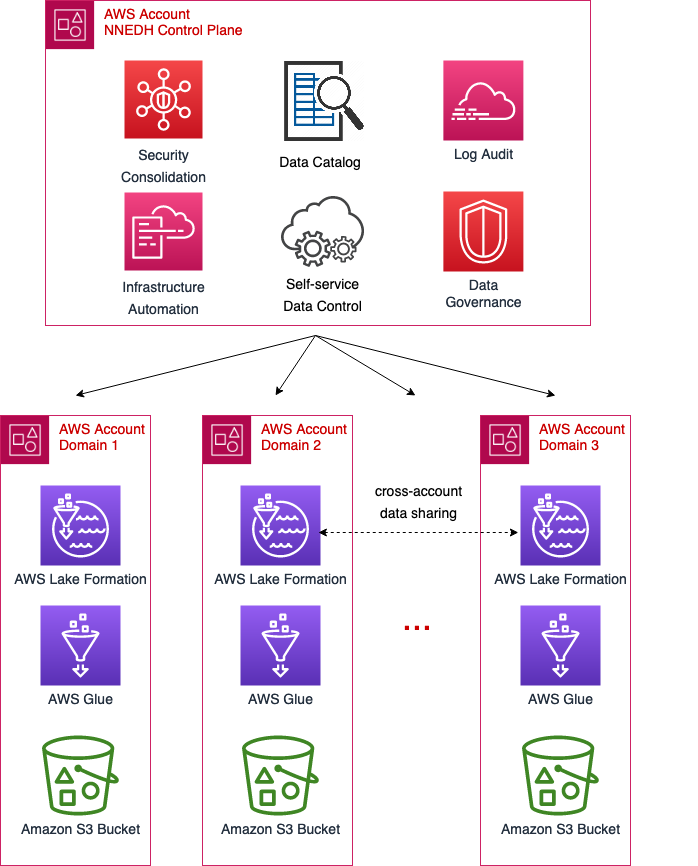
Information domains and knowledge belongings
To allow the scalability of knowledge domains throughout the group, it’s necessary to have a normal permission mannequin and knowledge entry sample. This commonplace should not be too restrictive in such a approach that it could be a blocker for particular use circumstances, but it surely ought to be standardized in such a approach to make use of the identical interface between the information administration and virtualization layers.
The info domains on NNEDH are applied by a assemble known as an setting. An setting consists of at the very least one AWS account and one AWS Area. It’s a office the place knowledge area groups can work and collaborate to construct knowledge merchandise. It hyperlinks the NNEDH management aircraft to the AWS accounts the place the information and compute of the area reside. The info entry permissions are additionally outlined on the setting stage, managed by the proprietor of the information area. The environments have three major parts: an information administration and governance layer, knowledge belongings, and elective blueprints for knowledge processing.
For knowledge administration and governance, the information domains depend on Lake Formation, AWS Glue, and CloudTrail. The deployment technique and setup of those parts is standardized throughout knowledge domains. This manner, the NNEDH management aircraft can present connectivity and administration to knowledge domains in a standardized approach.
The info belongings of every area residing in an setting are organized in a dataset, which is a set of associated knowledge used for constructing an information product. It contains technical metadata comparable to knowledge format, measurement, and creation time, and enterprise metadata such because the producer, knowledge classification, and enterprise definition. A knowledge product can use one or a number of datasets. It’s applied by managed S3 buckets and the AWS Glue Information Catalog.
Information processing could be applied in numerous methods. NNEDH supplies blueprints for knowledge pipelines with predefined connectivity to knowledge belongings to hurry up the supply of knowledge merchandise. Information area customers have the liberty to make use of some other compute functionality on their area, for instance utilizing AWS companies not predefined on the blueprints or accessing the datasets from different analytics instruments applied within the consumption layer, as talked about earlier on this publish.
Information area personas and roles
On NNEDH, the permission ranges on knowledge domains are managed by predefined personas, for instance knowledge proprietor, knowledge stewards, builders, and readers. Every persona is related to an IAM function that has a predefined permission stage. These permissions are primarily based on the everyday wants of customers on these roles. Nonetheless, to present extra flexibility to knowledge domains, these permissions could be personalized and prolonged as wanted.
The permissions related to every persona are associated solely to actions allowed on the AWS account of the information area. For the accountability on knowledge belongings, the information entry to the belongings is managed by particular useful resource insurance policies as a substitute of IAM roles. Solely the proprietor of every dataset, or knowledge stewards delegated by the proprietor, can grant or revoke knowledge entry.
On the dataset stage, a required persona is the information proprietor. Usually, they work carefully with one or many knowledge stewards as knowledge merchandise managers. The info steward is the information subject material knowledgeable of the information product area, liable for decoding collected knowledge and metadata to derive deep enterprise insights and construct the product. The info steward bridges between enterprise customers and technical groups on every knowledge area.
Enterprise enterprise knowledge catalog
To allow freedom and make the group knowledge belongings discoverable, a web-based portal knowledge catalog is applied. It indexes in a single repository metadata from datasets constructed on knowledge domains, breaking knowledge silos throughout the group. The info catalog permits knowledge search and discovery throughout completely different domains, in addition to automation and governance on knowledge sharing.
The enterprise knowledge catalog implements knowledge governance processes inside the group. It ensures the information possession—somebody within the group is liable for the information origin, definition, enterprise attributes, relationships, and dependencies.
The central assemble of a enterprise knowledge catalog is a dataset. It’s the search unit inside the enterprise catalog, having each technical and enterprise metadata. To gather technical metadata from structured knowledge, it depends on AWS Glue crawlers to acknowledge and extract knowledge buildings from the preferred knowledge codecs, together with CSV, JSON, Avro, and Apache Parquet. It supplies data comparable to knowledge kind, creation date, and format. The metadata could be enriched by enterprise customers by including an outline of the enterprise context, tags, and knowledge classification.
The dataset definition and associated metadata are saved in an Amazon Aurora Serverless database and Amazon OpenSearch Service, enabling you to run textual queries on the information catalog.
Information sharing
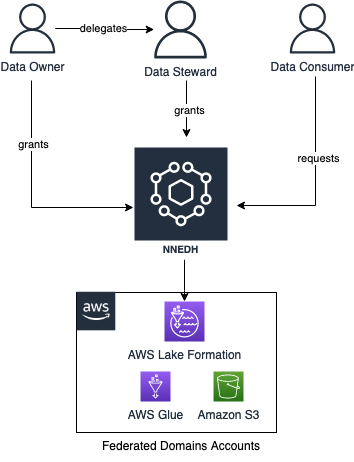
NNEDH implements an information sharing workflow, enabling peer-to-peer knowledge sharing throughout AWS accounts utilizing Lake Formation. The workflow is as follows:
- A knowledge client requests entry to the dataset.
- The info proprietor grants entry by approving the entry request. They will delegate the approval of entry requests to the information steward.
- Upon the approval of an entry request, a brand new permission is added to the particular dataset in Lake Formation of the producer account.
The info sharing workflow is proven schematically within the following determine.
Safety and audit
The info within the Novo Nordisk knowledge mesh lies in AWS accounts owned by Novo Nordisk enterprise accounts. The configuration and the states of the information mesh are saved in Amazon Relational Database Service (Amazon RDS). The Novo Nordisk safety structure is proven within the following determine.
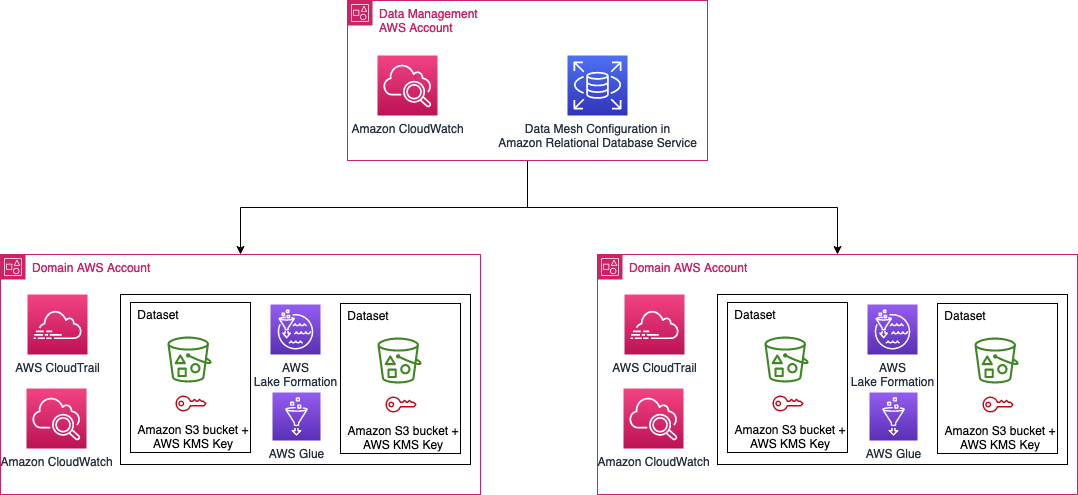
Entry and edits to the information in NNEDH must be logged for audit functions. We want to have the ability to inform who modified knowledge, when the modification occurred, and what modifications had been utilized. As well as, we’d like to have the ability to reply why the modification was allowed by that individual at the moment.
To fulfill these necessities, we use the next parts:
- CloudTrail to log API calls. We particularly allow CloudTrail knowledge occasion logging for S3 buckets and objects. By activating the logging, we are able to hint again any modification to any information within the knowledge lake to the one who made the modification. We implement utilization of source identity for IAM function periods to make sure person traceability.
- We use Amazon RDS to retailer the configuration of the information mesh. We log queries in opposition to the RDS database. Along with CloudTrail, this log permits us to reply the query of why a modification to a file in Amazon S3 at a selected time by a selected individual is feasible.
- Amazon CloudWatch to log actions throughout the mesh.
Along with these logging mechanisms, the S3 buckets are created utilizing the next properties:
- The bucket is encrypted utilizing server-side encryption with AWS Key Management Service (AWS KMS) and buyer managed keys
- Amazon S3 versioning is activated by default
Entry to the information in NNEDH is managed on the group stage as a substitute of particular person customers. The group corresponds to the group outlined within the Novo Nordisk listing group. To maintain observe of the one who modified the information within the knowledge lakes, we use the supply id mechanism defined within the publish How to relate IAM role activity to corporate identity.
Conclusion
On this publish, we confirmed how Novo Nordisk constructed a contemporary knowledge structure to hurry up the supply of data-driven use circumstances. It features a distributed knowledge structure, to scale the utilization to petabyte scale for over 2,000 inside customers all through the worth chain, in addition to a distributed safety and audit structure dealing with knowledge accountability and traceability on the setting to fulfill their compliance necessities.
The subsequent publish on this sequence describes the implementation of distributed knowledge governance and management at scale of Novo Nordisk’s trendy knowledge structure.
In regards to the Authors
 Jonatan Selsing is former analysis scientist with a PhD in astrophysics that has turned to the cloud. He’s at the moment the Lead Cloud Engineer at Novo Nordisk, the place he permits knowledge and analytics workloads at scale. With an emphasis on lowering the full price of possession of cloud-based workloads, whereas giving full good thing about the benefits of cloud, he designs, builds, and maintains options that allow analysis for future medicines.
Jonatan Selsing is former analysis scientist with a PhD in astrophysics that has turned to the cloud. He’s at the moment the Lead Cloud Engineer at Novo Nordisk, the place he permits knowledge and analytics workloads at scale. With an emphasis on lowering the full price of possession of cloud-based workloads, whereas giving full good thing about the benefits of cloud, he designs, builds, and maintains options that allow analysis for future medicines.
 Hassen Riahi is a Sr. Information Architect at AWS Skilled Providers. He holds a PhD in Arithmetic & Laptop Science on large-scale knowledge administration. He works with AWS prospects on constructing data-driven options.
Hassen Riahi is a Sr. Information Architect at AWS Skilled Providers. He holds a PhD in Arithmetic & Laptop Science on large-scale knowledge administration. He works with AWS prospects on constructing data-driven options.
 Anwar Rizal is a Senior Machine Studying marketing consultant primarily based in Paris. He works with AWS prospects to develop knowledge and AI options to sustainably develop their enterprise.
Anwar Rizal is a Senior Machine Studying marketing consultant primarily based in Paris. He works with AWS prospects to develop knowledge and AI options to sustainably develop their enterprise.
 Moses Arthur comes from a arithmetic and computational analysis background and holds a PhD in Computational Intelligence specialised in Graph Mining. He’s at the moment a Cloud Product Engineer at Novo Nordisk constructing GxP-compliant enterprise knowledge lakes and analytics platforms for Novo Nordisk international factories producing digitalized medical merchandise.
Moses Arthur comes from a arithmetic and computational analysis background and holds a PhD in Computational Intelligence specialised in Graph Mining. He’s at the moment a Cloud Product Engineer at Novo Nordisk constructing GxP-compliant enterprise knowledge lakes and analytics platforms for Novo Nordisk international factories producing digitalized medical merchandise.
 Alessandro Fior is a Sr. Information Architect at AWS Skilled Providers. With over 10 years of expertise delivering knowledge and analytics options, he’s keen about designing and constructing trendy and scalable knowledge platforms that speed up corporations to get worth from their knowledge.
Alessandro Fior is a Sr. Information Architect at AWS Skilled Providers. With over 10 years of expertise delivering knowledge and analytics options, he’s keen about designing and constructing trendy and scalable knowledge platforms that speed up corporations to get worth from their knowledge.
 Kumari Ramar is an Agile licensed and PMP licensed Senior Engagement Supervisor at AWS Skilled Providers. She delivers knowledge and AI/ML options that pace up cross-system analytics and machine studying fashions, which allow enterprises to make data-driven selections and drive new improvements.
Kumari Ramar is an Agile licensed and PMP licensed Senior Engagement Supervisor at AWS Skilled Providers. She delivers knowledge and AI/ML options that pace up cross-system analytics and machine studying fashions, which allow enterprises to make data-driven selections and drive new improvements.
[ad_2]